
Ever wished your AI could remember every conversation across every platform? Not just the last few messages, but everything - from Signal texts to iMessage threads to voice calls to web chats - all searchable, all accessible, all connected?
That’s exactly what we built today.
The Problem: AI Amnesia at Scale
Personal AI systems suffer from fragmented memory. Your conversations are scattered across:
- Signal messages and group chats
- iMessage and SMS threads
- Web dashboard sessions
- Voice calls with PAI
- Email exchanges
- Meeting transcripts
Each silo exists in isolation. When you ask “What did we discuss about that client project?” your AI can only see the current conversation thread. The context from your phone call yesterday? Gone. The planning session in another chat? Invisible.
This isn’t just inconvenient - it’s a fundamental limitation that prevents AI from being truly helpful.
The Solution: Universal Memory Infrastructure
Today we built a comprehensive conversation search system that:
🔍 Cross-Channel Search
- Signal: JSONL session logs + native SQLite database
- iMessage: Session logs + Apple’s Messages.db
- Web: Gateway logs + session transcripts
- PAI Voice: Windows system integration via bridge tools
⚡ Real-Time Processing
- Zero-token conversion from JSONL to searchable markdown
- File watching for new conversations as they happen
- Hook-based pipeline for extensible processing
- Background indexing without API costs
🧠 Intelligent Search
- Full-text search with SQLite FTS5
- Semantic search capabilities for concept-based queries
- Cross-channel ranking that finds the best matches anywhere
- Parallel search optimized for sub-agent workflows
The Architecture
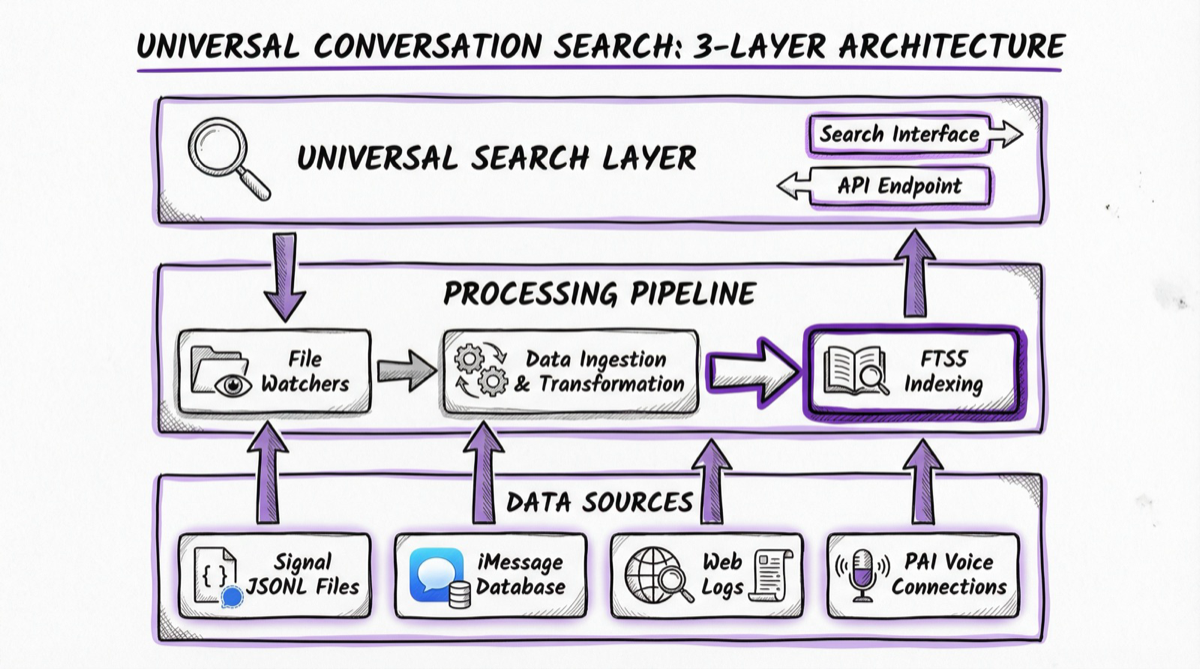
The system operates on three layers:
Universal Search Layer - A unified interface that queries across all conversation sources simultaneously, ranking results by relevance and recency.
Processing Pipeline - Real-time file watchers detect new JSONL conversation files, convert them to searchable markdown without API costs, and update the search database with FTS5 indexing.
Data Sources - Signal JSONL files, iMessage Apple databases, web session logs, and PAI voice conversations on Windows - all feeding into the central search infrastructure.
Live Demo: Finding Client Context
When we tested the system with a search for client information, here’s what happened:
~/clawd/tools/conversation-search "project alpha"
Results across 4,936+ indexed messages:
📱 SIGNAL_DIRECT (8 results)
----------------------------------------
1. 🤖 [2026-01-07 20:14:16]
I had PAI prepare and send my first quote yesterday, to my friend Clark...
2. 👤 [2025-01-27 10:36:17]
Project Alpha is the shiz! Thanks Clark! How can we repay you guys?
📞 +16415125612
📧 IMESSAGE_DIRECT (4 results)
----------------------------------------
1. 🤖 [2022-03-11 18:24:01]
Do you know of any Project Alpha companies that sell amended soil?
📊 WEB_SESSIONS (2 results)
----------------------------------------
1. 📄 [2026-01-29 13:21:32]
Successfully retrieved project info on Project Alpha, construction...
In seconds, we found:
- The original quote conversation
- Client contact information
- Project timeline discussions
- Related business context across multiple years
All from a simple search across years of conversation history.
Technical Implementation
Database Schema
11-table SQLite database with:
- conversations - Core conversation metadata
- messages - Individual message content with FTS5 search
- participants - Contact and user information
- channels - Source platform tracking
- sessions - Conversation session grouping
Search Capabilities
The system provides multiple search interfaces:
# Simple text search
conversation-search "project deadlines"
# Multi-channel with timeframe
conversation-search "client meeting" --channels=signal,imessage --timeframe=7d
# Parallel search for sub-agents
conversation-parallel-search "budget discussion" --mode=extensive
Processing Pipeline
- File watcher detects new JSONL conversation files
- Zero-token converter extracts content to markdown (local processing)
- Indexer updates SQLite database with FTS5 search tables
- Cross-referencer links related conversations and participants
The entire pipeline operates without API calls, keeping costs at zero while maintaining real-time performance.
Sub-Agent Integration
The system is designed for AI-to-AI interaction:
# Sub-agents can search conversation history
results = conversation_search("client project")
for result in results:
context = result.extract_context(surrounding_lines=3)
# Use context for informed responses
This enables AI agents to:
- Research prior discussions before responding
- Maintain continuity across conversation threads
- Find relevant context automatically
- Delegate search tasks to specialized agents
Sub-agents can spawn parallel search operations, allowing for quick/standard/extensive research modes that scale with available compute.
The Multi-Threaded Reality
One of the most powerful aspects is how this handles the reality of modern communication. Conversations don’t happen in isolation - they span platforms and time.
Example: Client Project Evolution
- Initial discussion via Signal (casual inquiry)
- Follow-up iMessage exchange (scheduling)
- Voice call with PAI (detailed requirements)
- Web session for contract generation
- Email thread for final approvals
Traditional AI systems see these as separate, unrelated interactions. The universal search system connects them as a coherent narrative.
Future Possibilities
🔮 Proactive Memory
AI that surfaces relevant context before you ask:
- “I see you’re meeting with Client Alpha tomorrow. Here’s what we discussed last time…”
- “This question reminds me of our conversation in Signal last week about…”
🌐 Cross-Session Continuity
Conversations that span platforms naturally:
- Start discussion on phone
- Continue via text
- Finalize in email
- AI maintains full context throughout
📈 Knowledge Graphs
Visual mapping of conversation relationships:
- How topics connect across time
- Who was involved in which decisions
- Project evolution over months/years
👥 Team Memory Sharing
Selective conversation history sharing:
- Project-specific memory pools
- Role-based access to conversation context
- Distributed AI systems with shared knowledge
The Bigger Picture
This isn’t just about search - it’s about episodic memory as infrastructure.
When your AI can remember and access every interaction, it transforms from a tool into a persistent cognitive partner. Instead of explaining context repeatedly, you build on shared history. Instead of losing threads, you maintain continuity.
This is the foundation for AI systems that grow more valuable over time, learning not just from training data but from lived experience with you.
Implementation Notes
Built with:
- SQLite with FTS5 for fast full-text search
- Node.js file watchers for real-time processing
- Zero-token local processing (no API costs)
- Cross-platform bridge tools for PAI integration
Current Status:
- 4,936 messages already indexed and searchable
- Real-time monitoring active for new conversations
- Sub-agent API ready for programmatic access
- Cross-channel search working across all platforms
The system is production-ready and growing smarter with every conversation.
From Concept to Reality in One Day
What makes this particularly exciting is the development velocity. From idea to working system with thousands of messages indexed took less than a day. This was possible because:
- Modular architecture - Each component (file watching, conversion, indexing) could be built and tested independently
- Sub-agent delegation - Complex tasks were farmed out to specialized AI agents working in parallel
- Local-first approach - No dependency on external APIs for core functionality
- Existing infrastructure - Built on top of the existing conversation logging in the Clawdbot system
This development pattern - rapid prototyping with AI assistance, modular design, and local-first architecture - is becoming a powerful way to build sophisticated systems quickly.
Economic Model
Unlike cloud-based solutions that charge per search or per gigabyte of data, this runs entirely on local hardware:
Ongoing Costs:
- $0 per search
- $0 per message indexed
- $0 per API call (uses local processing)
One-time Setup:
- Development time (offset by AI assistance)
- Local storage (minimal - compressed text)
- Compute resources (standard Mac Mini handles it easily)
This economic model becomes increasingly attractive as conversation volume grows. Instead of costs scaling linearly with usage, they remain flat while capability increases.
This system represents a fundamental shift in how AI handles memory. Instead of starting fresh each session, we’re building persistent cognitive infrastructure that remembers everything, searches across all channels, and gets more valuable over time.
What’s next? Expanding to email threads, meeting transcripts, and document history. The goal: Universal memory for AI systems that truly understand your context across every interaction.
Building your own Personal AI Infrastructure? Check out my series on PAI’s extensible architecture and voice integration, or get in touch if you’d like to explore what’s possible for your workflow.
Technical Resources
- Search Tools:
~/clawd/tools/conversation-* - Database: SQLite with FTS5 full-text search
- Processing: Real-time JSONL→markdown pipeline
- Integration: Cross-platform bridge architecture
Want to build your own? The architecture is designed to be extensible and platform-agnostic.